Building and testing a simple deep learning object detection application
Deep learning is hot currently. Really hot. The reason for this is that there’s more data available than ever in the space of perception. By perception I mean tasks such as object recognition in images, natural language processing, speech detection etc. Basically anything where we generate copious amounts of data every day. Many companies are putting this data to good use. Google, Facebook, Nvidia, Amazon etc. are all heavy in this space since they have access to most of these data. We as users happily give it to them through all our social media posts and online storage utilization. In any case I wanted to give you all a flavor of what you can do with a relatively small convolutional neural network trained to detect many different objects in an image. Specifically we will use a network architecture known as MobileNet which is meant to run on smaller devices. Luckily for us you can get access to pre-trained models and test it out. So that’s exactly what we’ll do today.
The data foundation
The model has been trained on the COCO dataset (Common Objects in Context). Just as it sounds like this dataset contains a lot of images with objects we see quite often in everyday life. Specifically it consists of 300k images of 90 different objects such as
- Fruit
- Vehicles
- People
- Etc.
The model
The model we are using is the “Single Shot Multibox Detector (SSD) with MobileNet” located here and takes a little while to download. It’s stored using Google’s Protocol Buffers format. I know what you’re thinking: Why oh why invent yet another structured storage format? In Google’s defense this one is pretty cool. Basically it’s a language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
Convolutional neural networks
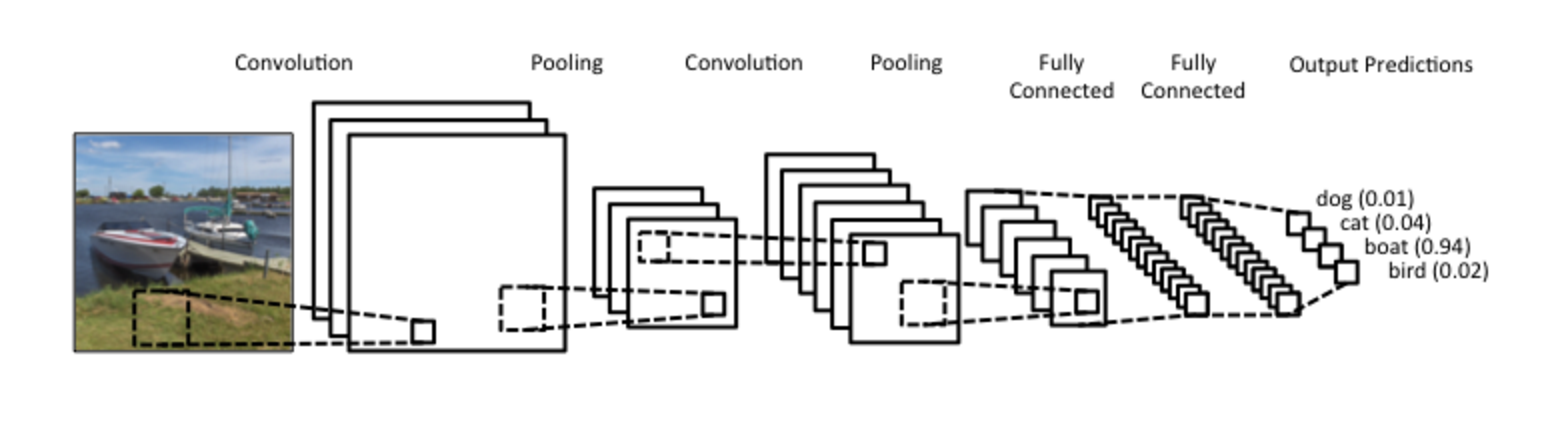
Before we have a look at the results let’s give a quick introduction to what convolutional neural networks really are and why they are more successful at image analysis than normal multi-layered perceptrons. The whole idea behind using convolutional neural networks is that we need the network to be translation and rotation invariant. This just means that we need to be able to recognize an object no matter where in the image it resides. One way to achieve this is to swipe a patch reacting to certain patterns over the image. Think of it as a filter that lights up when it detects something. Of course we don’t know what we are looking for and therefore these filters are learned during training. In general in deep learning we learn lower level features in the initial layers while the later layers captures more elaborate features. This is pretty cool as we can save initially trained early layers and reuse them in other models.
Results
The video below was shot from my cell phone while the modeling team was working. As you can see the model does indeed identify some objects quite successfully. But it also fails to detect many of them. There are many reasons for this. One of them is that this model is optimized for speed and not for performance.

In this short post I showed you how it’s possible to utilize a previously fitted convolutional neural network and classify objects in a retrospective video. However this can be extended into a live object detection from a webcam or a surveillance camera. If you’re interested in doing this yourself have a look at Tensorflow’s example here.
Happy hacking!